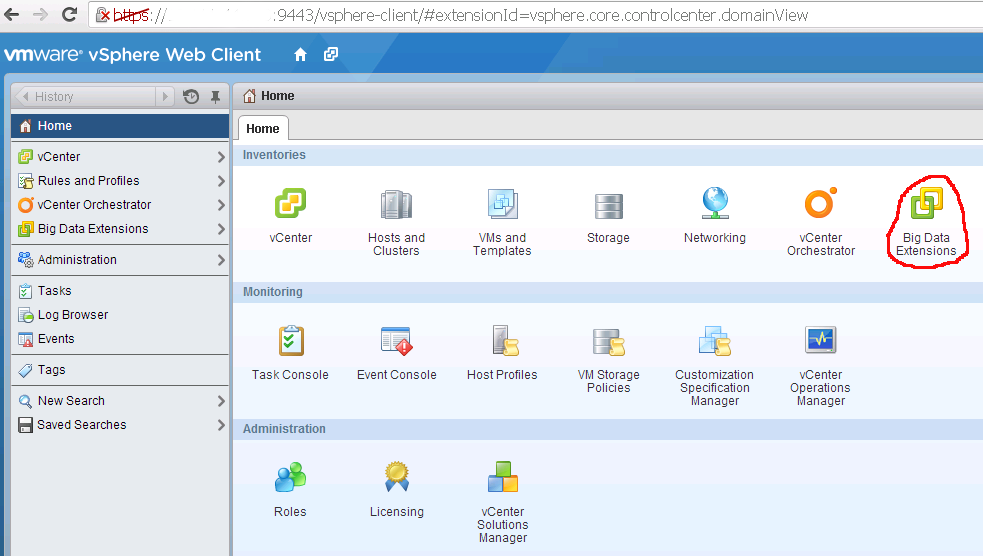
After deploying Serengeti Management Server using OVF, it would be possible to install Big Data Extensions plugin in vCenter Server. Follow the instructions for doing this. After a Logout and Login (necessary), you will see Big Data Extensions plugin in vSphere Web Client Home, Inventories.
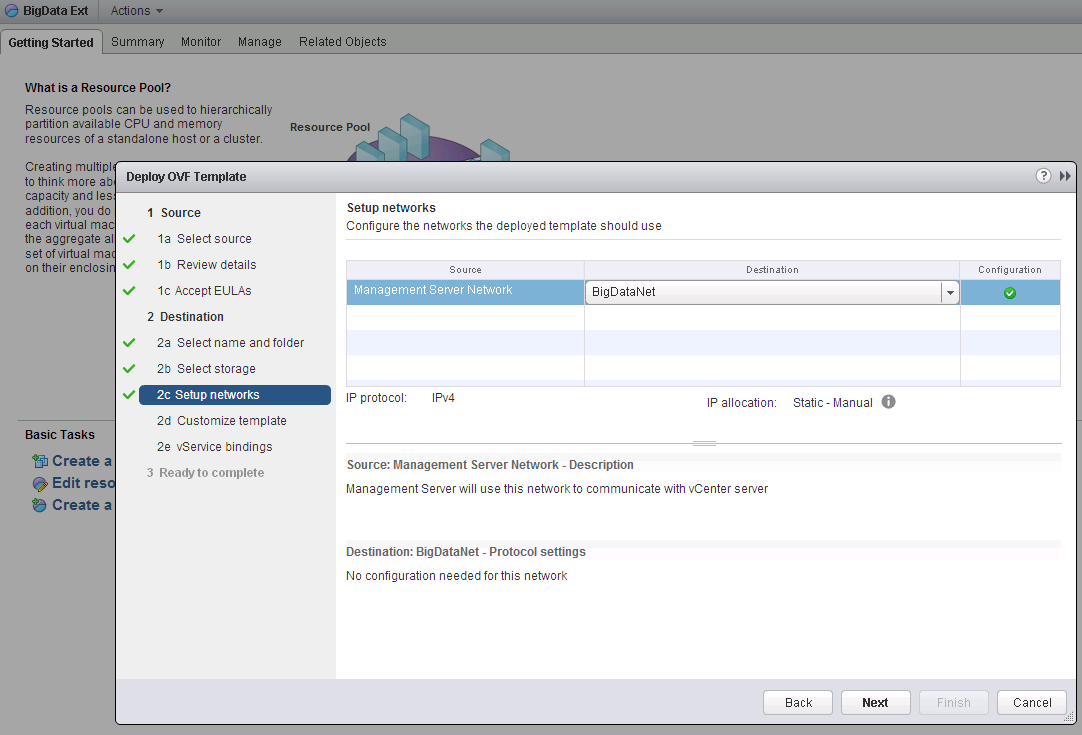
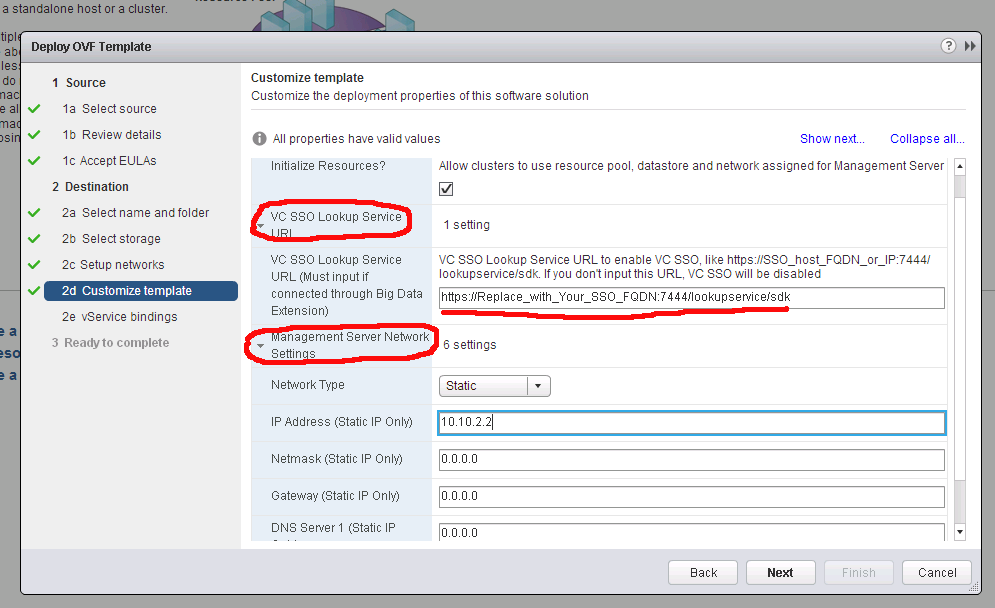
Next step is connecting Big Data Extensions plugin to Serengeti Management Server. For a successful connection, 2 conditions should be met: First, Serengeti Management Server should be reached by vCenter in terms of networking. Ping is not blocked by default, so vCenter should be able to ping Serengeti Server. Secondly, SSO Lookup Service URL should be correct. If it’s not correct, you will get an error like: “Connection failed! Check the server has enabled SSO.” If you are not sure if SSO URL is entered and works properly, try to re-enter SSO Lookup service URL manually:
Login to Serengeti server and issue these commands:
– sudo /opt/serengeti/sbin/EnableSSOAuth https://VC-FQDN:7444/lookupservice/sdk
– sudo service tomcat restart
In my case, I first got the following error:
“com.vmware.vim.vmomi.core.exception.CertificateValidationException: Server certificate assertion not verified and thumbprint not matched
Return code is: SslHandShakeFailed
Please check if sso lookup service https url is correct, and sso service work normally.”
The issue was that I entered URL by IP and certificate was generated using FQDN. So, I recommend using FQDN of vCenter and not IP address.
Also, check the time of Serengeti server to by synced with vCenter.