You probably know about AWS CDK: “The AWS Cloud Development Kit (AWS CDK) lets you define your cloud infrastructure as code in one of its supported programming languages.“; Sceptre (open source tool by Cloudreach) adds an extra layer of power for DevOps engineers: “Sceptre is a tool to drive CloudFormation. Sceptre manages the creation, update and deletion of stacks while providing meta commands which allow users to retrieve information about their stacks.”
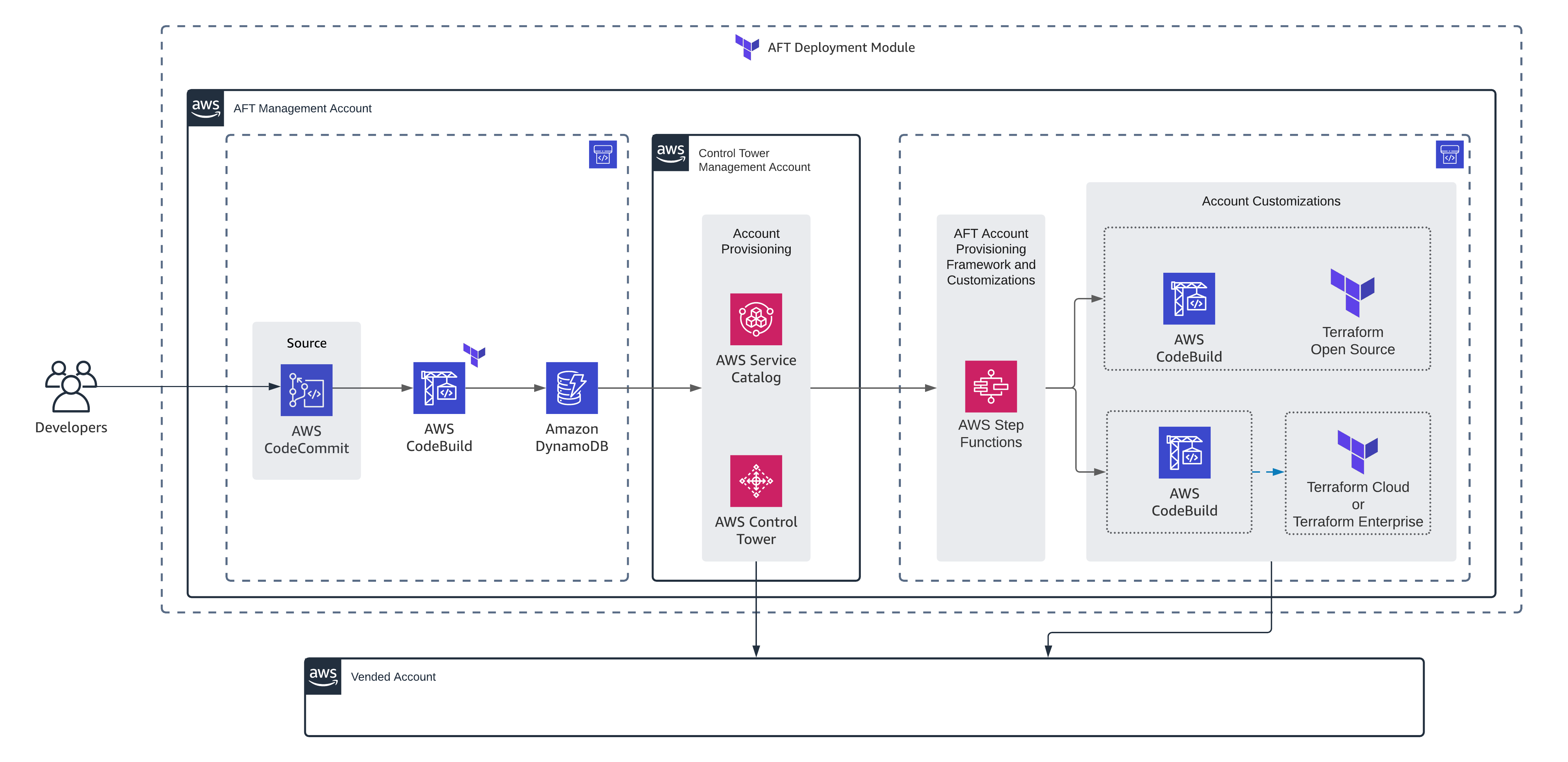
As you see, they both have something important in common: CloudFormation. the output of an AWS CDK program is an AWS CloudFormation template and Sceptre leverages CloudFormation templates to streamline stack deployments. Think of Sceptre as the conductor that orchestrates your CDK-defined infrastructure across multiple environments. It lets you focus on writing concise CDK code while Sceptre handles the environment-specific configurations and deployments. I found this article in Dev community website a good and brief explanation about Sceptre. The good news is that Sceptre supports AWS CDK as templating source. The following diagram makes it clear how this works:

Managing diverse environments such as Development, Test, Acceptance, Staging and numerous production clusters with unique configurations can be a nightmare. Sceptre saved my day by simplifying deployments across them all using the same infrastructure code (plain CloudFormation templates, Troposphere or CDK)! Also, separating configuration plane from code plane and ability to pass parameters across the stacks makes it very useful for DevOps teams. I used troposphere for templating but its development lost its momentum and couldn’t keep up with official CloudFormation updates. So, when I heard about AWS CDK support in Sceptre, it was like dream comes true!
I gave it a try and I’m very happy with it. I didn’t have to change anything in the existing code but instead leveraged AWS CDK for new stacks. Amazingly, cross-stack references, hooks, parameter handling features all worked as before. This is possible because of modular design of sceptre and its reusability capabilities.
Now, Let’s have a look at an example. The following python code creates a simple OpenSearch cluster using its CDK construct:
from aws_cdk import CfnOutput, CfnParameter
from aws_cdk import aws_certificatemanager as acm
from aws_cdk import aws_route53 as r53
from aws_cdk import aws_iam as iam
from sceptre_cdk_handler import SceptreCdkStack
from aws_cdk import aws_opensearchservice as opensearch
from aws_cdk import aws_ec2 as ec2
# Important: Notice how it subclasses SceptreCdkStack and passes **kwargs into the base class's
# __init__(). This is important to maintain compability with the different deployment_types.
class OpenSearchStack(SceptreCdkStack):
def __init__(self, scope, id: str, sceptre_user_data: dict, **kwargs):
super().__init__(scope, id, sceptre_user_data, **kwargs)
# If you want to pass parameters like you do elsewhere in Sceptre, this works great!
self.num_data_nodes = CfnParameter(self, 'NumOfDataNodes', type='Number')
self.data_node_type = CfnParameter(self, 'DataNodeType')
self.data_node_size = CfnParameter(self, 'DataNodeSize', type='Number')
self.os_username = CfnParameter(self, 'Username', default='flybits-admin')
self.warm_node_type = CfnParameter(self, 'WarmNodeType', default='ultrawarm1.medium.search')
self.master_node_type = CfnParameter(self, 'MasterNodeType', default='r5.large.search')
self.num_az = int(sceptre_user_data['NumOfAZs'])
self.version = sceptre_user_data['Version']
self.num_of_warm_nodes = sceptre_user_data['NumOfWarmNodes']
self.num_of_master_nodes = sceptre_user_data['NumOfMasterNodes']
if self.num_of_warm_nodes == 'None':
self.num_of_warm_nodes = None
if self.num_of_master_nodes == 'None':
self.num_of_master_nodes = None
slr = iam.CfnServiceLinkedRole(
self, "Service Linked Role",
aws_service_name="es.amazonaws.com"
)
self.os_domain=opensearch.Domain(self, "OS_Domain",
version=opensearch.EngineVersion.open_search(version=self.version),
enable_version_upgrade=True,
capacity=opensearch.CapacityConfig(
data_node_instance_type=self.data_node_type.value_as_string,
data_nodes=self.num_data_nodes.value_as_number,
warm_nodes=self.num_of_warm_nodes,
warm_instance_type=self.warm_node_type.value_as_string,
master_nodes=self.num_of_master_nodes,
master_node_instance_type=self.master_node_type.value_as_string,
),
zone_awareness=opensearch.ZoneAwarenessConfig(
availability_zone_count=self.num_az
),
ebs=opensearch.EbsOptions(
volume_type=ec2.EbsDeviceVolumeType.GP3,
volume_size=self.data_node_size.value_as_number
),
encryption_at_rest=opensearch.EncryptionAtRestOptions(
enabled=True
),
node_to_node_encryption=True,
enforce_https=True,
fine_grained_access_control=opensearch.AdvancedSecurityOptions(
master_user_name=self.os_username.value_as_string,
)
)
self.resource_arn = self.os_domain.domain_arn + "/*"
self.os_domain.add_access_policies(iam.PolicyStatement(
actions=["es:*"],
effect=iam.Effect.ALLOW,
principals=[iam.AnyPrincipal()],
resources=[self.resource_arn]
))its sceptre configuration looks like the following:
template:
type: cdk
# The path is always within your project's templates/ directory.
path: logging/opensearch.py
deployment_type: bootstrapless
bootstrapless_config:
file_asset_bucket_name: !stack_attr template_bucket_name
# It can be useful to apply the same prefix as your template_key_prefix to ensure your
# assets are namespaced similarly to the rest of Sceptre's uploaded artifacts.
file_asset_prefix: "cdk-assets"
class_name: OpenSearchStack
# Parameters are DEPLOY-TIME values passed to the CloudFormation template. Your CDK stack construct
# needs to have CfnParameters in order to support this, though.
parameters:
NumOfDataNodes: "2"
DataNodeType: "r6g.large.search"
DataNodeSize: "100"
sceptre_user_data:
NumOfAZs: "2"
RoleNeeded: true
Version: "2.7"
NumOfWarmNodes: None
NumOfMasterNodes: None
In specific look at the flexibility of introducing values for parameters in code. In sceptre we have 2 ways of passing values: first is parameters which is equivalent to setting values for CloudFormation parameters and the other is sceptre_user_data which is specific to sceptre and its resolvers take care of assigning the values in code. I brought both in code to show their use case. In specific, for variables like NumOfWarmNodes which their value can be a number or None , you can’t use parameters because it doesn’t accept 2 different types; instead sceptre_user_data is very helpful and you can easily assign None or a Number (please see the code)
As conclusion, if you are already using CloudFormation or AWS CDK and you are looking for a flexible and structured way of managing multiple environments using the same infrastructure as code, a combination of Sceptre and AWS CDK is highly recommended.