We recently started to migrate from CAS (Kubernetes AutoScaler) and EC2 ASG (AutoScaling Groups) to Karpenter in some of our EKS clusters. So far so good and I’m happy with the results, especially because of excellent use of Spot instances 🙂 and reducing our EC2 costs but I noticed something interesting about CloudTrail logs.
I noticed that our CloudTrail costs in the accounts with Karpenter are slightly increased. Looking closer, I saw a lot of UpdateInstanceInformation Events and the Identity source for these events was Karpenter Node Role making calls to AWS SSM. It makes sense because Karpenter actually comes with SSM agent and SSM Agent calls this API in Systems Manager service every 5 minutes to provide heartbeat information. So, if you configured CloudTrail to log all management events, you will see this event more often when you have an EKS cluster with Karpenter.
Recently I worked on a governance project and I decided to take a look at AWS Control Tower. I found it much more mature than few years ago with good documentation. Also, Landing Zone is integrated in Control Tower which is really nice.
Having said that, especially when it comes to automation using code, Control Tower needs some improvements. Basically, there is no API for Control Tower and things such as creation and managing guardrails in CT can’t be done using code.
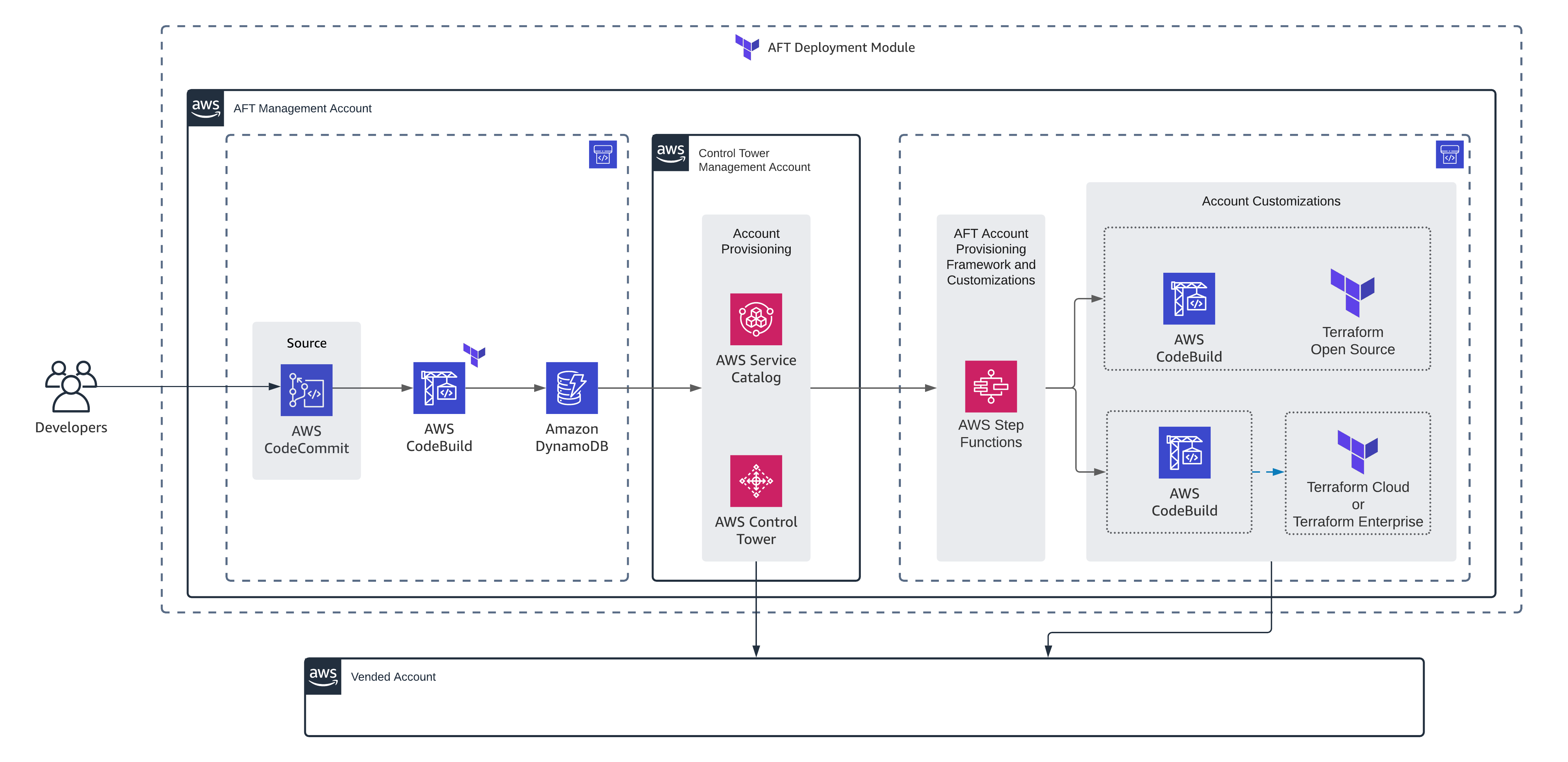
Although some operations in Control Tower can be automated. One of the nice things in Control Tower is Account Factory which enables us to create and manage AWS Accounts in an Organization’s landing zone. Even nicer, there is a GitOps model to automate the processes of account provisioning and account customization in AWS Control Tower, named Account Factory for Terraform (AFT). The official document explains how to deploy AFT very well. It will create a couple of lambda functions and pipelines; also Step functions and Service Catalog are configured in a way to process requests to create and manage AWS Accounts using Terraform.
When Account Factory is deployed, we need to work with 4 repositories that will trigger pipelines; each repository is responsible for a specific operation. For example, to create a new AWS Account you have to use aft-account-request repository. It uses a Terraform module with the same name and usually works well, considering you followed the documentation.
So far so good but if something goes wrong, the troubleshooting is a bit hard because this terraform module is very simple and you have to have a good understanding of how the whole workflow works to be able to troubleshoot. Let me give an example: when I was pushing one request to create a new AWS account, I wrote the name of organization unit (OU) all lower case while apparently the name of OU is case sensitive. When I pushed the code, terraform pipeline succeeded with no error because it just inserts a key/value pair in a DynamoDB table but obviously no account was created. To troubleshoot, I had to go over the whole procedure and check the logs of lambda functions and code builds to figure out the root cause of the issue. It was a great experience for me and gave me a deep knowledge of the procedure but it can be difficult for operators who don’t have access to those lambda functions and Codepipelines which are located in sensitive AWS Accounts.
As I’ve shown, if you are planning to use AFT, don’t rely only on terraform pipelines and think about some ways to facilitate troubleshooting. For example, I would recommend publishing all the logs of lambda functions, AWS Step Functions and AWS Codebuild projects to a log collector and let operators observe those logs even if terraform apply succeeds.
We know AWS Cloudwatch: A very good monitoring service which we use to check metrics (or logs) of AWS resources. Personally I always used CloudWatch in its simplest way which is choosing a namespace, dimension and then the desired metric (AWS one or Custom) and playing with the time frame.
Sometimes it’s needed to do some more complex operation to monitor a situation instead of a simple metric. Especially when you want to create an alert. CloudWatch has this capability to do some math operations; you can find more information here but I will explain a use case which I faced recently. It’s related to long expected RabbitMQ broker of Amazon MQ.
Not long time ago, AWS announced availability of RabbitMQ as a broker of Amazon MQ service. RabbitMQ is very popular for distributed systems, so, a managed service from AWS will help DevOps teams a lot 🙂
This is familiar to those who know RabbitMQ but in our use case we wanted to receive an alert when the rate of Acknowledging messages is considerably less than rate of publishing messages to queues. We came up with the following Cloudformation code to implement this alarm:
This is more an informational post that may help others to feel less miserable in the same situation as I was! The scenario is this:
You are updating an ECS cluster via AWS CloudFormation but for whatever reason the cluster doesn’t stabilize. So, you see the stack is in UPDATE_IN_PROGRESS state and you don’t receive any message in CloudFormation Events page. If you can’t troubleshoot the issue with ECS and take no action, It will take 3 hours before CloudFormation timeouts and display a message! At this point, as you can guess, CloudFormation will rollback. Situation can be even worse if Rollback can not be proceeded successfully (in our case, there was a lack of resources preventing update and rollback). Again, CloudFormation will stuck in UPDATE_ROLLBACK_IN_PROGRESS state and will timeout after 3 hours! In a conversation I had with AWS support, they said this time is hard-coded and can’t be changed at the moment!
So, in such a situation: Keep Calm And Troubleshoot!
Lambda functions are just another great tool provided by AWS to solve issues in a modern way! Using Lambda functions, you can run a micro service without a need to have a server and think of how to configure and maintain it!
There are lots of use cases for Lambda functions; here I used it to implement a service which sends alerts in case there is a slow query running in RDS. Of course slow queries are important for developers as it helps them to debug better and improve performance of the application. You can find the code here but there are some other things to be considered:
As you may know, there are some ways to trigger a Lambda function. In this case, using CloudWatch Events to schedule it periodically makes sense.
The lamda function should have some permissions to get RDS Logs and send alerts using SNS. To find out how to define required rules, please see this AWS documentation. You are also asked to do this when creating Lambda function.
There is a parameter named ‘distinguisher’ which is actually the keyword specifying the occurrence of slow query. For ‘Postgresql’ RDS it can be ‘
Parameters Group in RDS should be configured to log slow queries. To know how to do this please see AWS documentation or this guide:Enabling slow query log on Amazon RDS
If you use ElasticSearch for Log analysis, you probably need to have backup and retirement strategy. It’s very handy to store a backup on a S3 bucket and configure lifecycle on that S3 bucket. I know there is a plugin (curator) that can do this but I preferred to use another approach and use ElasticSearch REST API’s. Here is a step to step guide about how to achieve this:
I’m really a big fan of open source concept as I’ve seen its benefits in improving quality of the world we are living in. Especially in a country where access to high quality materials is hard, it’s the only legal and fair way to learn more and be able to contribute. The other way to access valuable data/tools actually is cheating! and I really hate that. I’m proud that I have never cheated in my whole educational life whereas it was really common to cheat and win! Open source development is also taking and giving which satisfies your spirit!
One of the things I really love working with public cloud (in specific, AWS) is its openness and nice documentation which enables everyone to implement their ideas that is in line with Open Source concept. In addition, AWS emphasis on DevOps and its integration with open source tools such as Chef, Packer, … has helped in fortifying open source culture in public cloud context. You can find great tools and utilities which are developed for AWS. In my next post, I will introduce a project that I have started and any contribution is more than welcomed!
I recently had difficulties using Chocolatey chef cookbook to install packages on Windows 2012 R2 EC2 instances via Packer. For those who have issues, I would recommend to use an older version of chocolatey cookbook (12_5_fix). A solution is to modify Berksfile with the following:
On the new exciting journey that I started in public cloud, today I earned AWS Solutions Architect (Associate Level) certificate. It was a bit more challenging than what I expected but it was fun! For those who want to pass the exam, in my opinion despite what’s said about the focus of exam on VPC, RDS, high availability and scalability; the truth is that you should get familiar with almost all of the services and update yourself with new ones. For example, to my surprise I didn’t have any direct question about RDS but instead 5 or 6 questions about SQS and SWF and 1 question about Kinesis! I suppose questions are randomly selected and others may have different experiences but it’s a good idea to know basics of all the services. Of course, VPC, security, high availability and scalability are super important and you must be fluent in them but all I say is that they are not enough for passing the exam. Also, expect more scenario sort of questions which include different concepts rather than direct one sentence questions that you may find in internet.
So, if you are preparing for this exam, work harder and good luck!